
Englezi imaju šalu da “when you assume, you are making and ass of u and me” [direktno ću prevesti, obzirom da se radi o igri riječima, ”kada radiš pretpostavku, radiš magarca od sebe i mene”]. A to je ono što mi radimo u statistici cijelo vrijeme – pretpostavljamo, a samim time magarčimo sebe i druge.
Radimo svakakve pretpostavke, npr. pretpostavljamo da se većina (ako ne i sve) varijable distribuiraju prema normalnoj distribuciji; pretpostavljamo da je Likertova skala od sedam stupnjeva intervalna a ne ordinalna; prepotstavljamo da su naši ispitanici (u potpunosti) nezavisni jedni od drugih; itd.
No, glavna pretpostavka, bez koje nema statistike kojom se mi ovdje bavimo jest da je nul-hipoteza točna! A detaljnije o nul-hipotezi u nastavku.
Sjetimo se objave o Uzorku i populaciji gdje smo objasnili čemu služe uzorci. Sva statistika bila bi nepotrebna kada bismo uvijek imali pristup cijeloj populaciji. Nažalost, ili na sreću, (skoro pa) nikad nemamo pristup cijeloj populaciji, stoga se oslanjamo na uzorke da bismo zaključivali o populaciji. Obzirom da uzorkujemo iz populacije, naravno da će u tom uzorku biti svega, ali idealno, uzorak će biti dobar reprezentant populacije. Jedina situacija u kojoj imamo pristup cijeloj populaciji su simulacijske studije. Jednu kratku sam ja napravio. Imamo našu populaciju od 10000 djece, i znamo da im je prosječna inteligencija 100 IQ bodova. A to znamo jer sam ja to tako definirao (crvena linija). Kada uzorkujemo, neki uzorci će imati veću prosječnu inteligenciju, neki manju, no očekujemo (pretpostavljamo!) da će svi oni biti prilično blizu pravoj aritmetičkoj sredini populacije. Pa pogledajmo sliku:
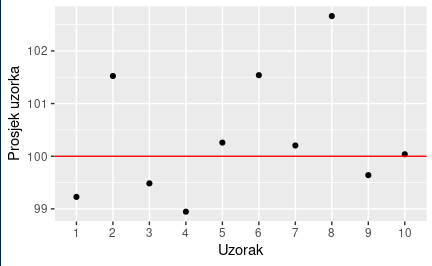
Neki uzorci su imali IQ 99, neki 101.5, neki 103, itd.
Nul-hipoteza
U ovom jednostavnom slučaju (kojeg bismo testirali t-testom za jedan uzorak) nul hipoteza je da nema razlike između aritmetičke sredine uzorka i aritmetičke sredine populacije. Razumijem da je možda malo kontradiktorno uspoređivati aritmetičku sredinu populacije (za koju sam pred 2 rečenice rekao da je ne možemo znati) ali mi možemo uzeti bilo koji broj. Recimo da nas zanima dolazi li naš uzorak iz populacije djece koja imaju prosječno 5 prijatelja. Tada bi uspoređivali prosjek našeg uzorka s brojem 5 za koji (temeljem prijašnjih istraživanja, ili temeljem bilo kojeg drugog razloga) vjerujemo da predstavlja nešto čemu treba težiti.
Svaka statistička analiza se svodi na to da testiramo tu nul-hipotezu od koje krećemo. Koliko god (malo) znali o temi istraživanja, krećemo s idejom da nikakva razlika ne postoji, odnosno, očekujemo (kad provodimo t-test za jedan uzorak) da će aritmetička sredina našeg uzorka iznositi točno onoliko koliko očekujemo (npr. 5 prijatelja). Jednom kad izračunamo rezultate, sjednemo i gledamo koliko smo zapravo iznenađeni što aritmetička sredina našeg uzorka ne iznosi točno koliko iznosi naše očekivanje.
Plastičniji primjer je t-test za nezavisni uzorak kojim uspoređujemo aritmetičke sredine dviju grupa ispitanika, npr. dječaka i djevojčica u broj olovki koje imaju u pernici. Ako znamo da nul-hipoteza označava pretpostavka da razlike nema, isto možemo uobličiti tako da kažemo razlika u prosječnom broju olovki između dječaka i djevojčica iznosi nula. Naša nul hipoteza izgleda ovako:
Očekujemo da i dječaci i djevojčice imaju jednaki prosječan broj olovki u svojoj pernici. Ili, još plastičnije da aritmetička sredina olovki kod dječaka = aritmtičkoj sredini olovki kod djevojčica. Pogledajmo sljedećih nekoliko primjera. U ovom, što bismo zaključili?
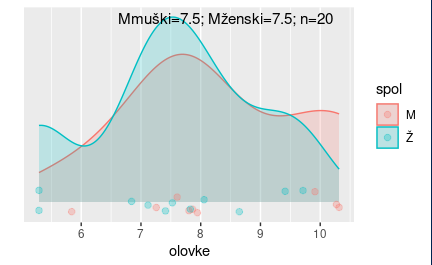
Uzorkovali smo 10 dječaka i 10 djevojčica, te saznali da su im prosjeci isti. Koliko bismo bili iznenađeni da dobijemo ovakav rezultat? Nimalo, pod uvjetom da je nul-hipoteza točna. To je točno ono što bismo i očekivali.
Pogledajmo drugu sliku:
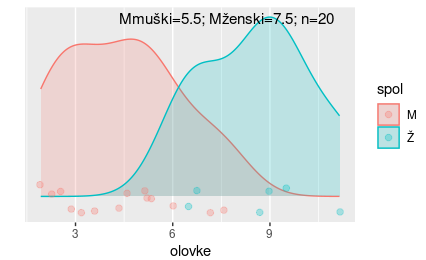
Opet, gledamo sliku očekujući da ove dvije grupe dolaze iz iste populacije (imaju jednak prosječan broj olovki). Jeste li, i koliko iznenađeni dobiti ovakav rezultat pod uvjetom da je nul-hipoteza točna?? Ja bi bio, i to jako iznenađen. Toliko bih bio iznenađen da bih doveo u pitanje pretpostavku da je nul-hipoteza točna. A onda bih rekao sam sebi:
“Postoji stvarno mala vjerojatnost da bih opazio ovakav rezultat kad bu nul-hipoteza bila točna. Ergo, odbacujem nul-hipotezu! Ona mi ne znači ništa! Nije točna. Ali, što to onda znači? To onda znači ako ove dvije grupe nemaju istu aritmetičku sredinu – sigurno imaju različitu aritmetičku sredinu!”
Ovaj cijeli postupak naziva se NHST (nul-hypothesis significance testing) i predstavlja kamen temeljac većine predmeta koji se bave statistikom. Mi o populaciji zaključujemo pokušavajući pronaći dokaze protivne našem očekivanju. Tražimo tzv. crnog labuda. Zašto? Je li lakše pokazati da su svi labudovi na svijetu bijeli tako da pronađemo sve bijele labude, ili je lakše potražiti samo jednog crnog labuda da bismo odbacili tvrdnju da su svi labudovi bijeli?
Pažljivijem čitatelju u oko će uskočiti (barem) jedan problem s NHST. Ako su definicije zaista takve kakvima ih navodim (a jesu, barem pretpostavite da jesu), znači li to da ja nikad sa sigurnosti ne mogu znati ima li ili nema razlike u populaciji? Točno tako – NHST nam govori kolika je vjerojatnost da bismo opazili ovakav (ili ekstremniji) rezultata kad bi nul hipoteza bila točna. Primjećujete da nam ne govori je li točna ili ne, nego samo s kojom vjerojatnosti bismo došli do baš ovih rezultata kad bi nul bila točna.
S druge strane, govori li nam o tome je li kriva? Nažalost, ni to nam ne govori, kada u uzorku dobijemo dvije aritmetičke sredine koje su skoro pa iste, mi i dalje govorimo o vjerojatnosti kojom bismo opazili upravo ovakav rezultat (da su dvije aritmetičke iste) kad bi nul bila točna. Znate i sami da bi u tom slučaju, ta vjerojatnost bila super visoka, skoro 100% (predzadnja slika). S druge strane, koja je vjerojatnost da bismo dobili rezultat sa zadnje slike kad bi nul bila točna? Super mala, možda 0,000001% (primjećujete da nije apsolutna nula).
Znam što mislite, bilo bi idealno kad bi postojao nekakav broj, nekakva granica koja bi nam rekla koliko iznenađeni moramo biti da budemo dovoljno sigurni da takva razlika postoji i u populaciji. Pa pametniji ljudi od nas su se pobrinuli da to bude jedan lako pamtljiv broj (toliko prstiju na ruci imamo!) – 5. Tako da, ako bi vjerojatnost da opazimo ovakav ili ekstreminij rezultat u našem uzroku bila manja od 5% (ili manja od 0.05) tada slobodno možemo zaključiti da bismo takvu razliku našli i u populaciji. I voila, ovime smo pokrili i koncept zvan p-vrijednost!
Do sljedećeg puta.