
matia
2023-12-06
library(tidyverse)
library(tidytext) Unos Excelice
Sljedeće, ubacimo bazu u R. Da bismo to napravili, kliknemo na Upload, nađemo našu bazu i upload-amo je na Cloud:
Jednom kad smo to napravili, onda kliknemo gore na Import Dataset:
Razbijanje odgovora
Pazite da se desno od znaka jednakosti nalazi TOČNO ono ime kojim je nazvana vaša baza Meni je New_Microsoft_Excel_Worksheet_2_ i to vbidim u Environmentu (mora se tamo nalaziti ako ste ju dobro unijeli)
brutto_baza=intervju_primjer #umjesto excel.file upišite ono ime kako je nazvana vaša baza!Prije unosa (jer je lakše nego u R-u) promijenite imena varijabli i unesite ih na sljedeći način: ispitanik – ime, ili redni broj ili na koji god ćete već način razlikovati jednog ispitanika od drugog spol – i bilo koja druga informacija za koju smatrate da je bitna (a možda niti spol nije) … – dakle, tu unosite bilo koju drugu info o ispitaniku koju smatrate bitnom (npr. drzava…) pitanje – postavljeno pitanje, pazite, jer ćete isto pitanje imati postavljeno različitim ispitanicima, da bi R znao da se radi o istom pitanju, ono mora biti IDENTIČNO (u razmak, zarez, veliko slovo, itd.) isto tako, bilo bi jako dobro kad ne biste pisali CIJELO pitanje već da umjesto cijelog pitanja napišete skraćno pitanje, npr. umjesto pitanja: Kako ste zadovoljni s trenutnom ponudom? Smjerova na diplomskom studiju na ekonomskom fakultetu u rijeci. napisati “zadovoljstvo ponudom smjerova” kako bi grafovi kasnije bili pregledniji. To ću ja napraviti u narednom kodu, a vi morate PRILAGODITI TAJ KOD SVOJIM PITANJIMA! tekst – odgovor ispitanika spremate u varijablu “tekst” kako bi ostatak koda radio kako i treba!
Nazivanje pitanja kraćim riječima (ovo možete i u Excelici, ako vam je lakše, prilikom unosa pdoataka) napraviti!
brutto_baza=brutto_baza %>%
mutate(pitanje2=case_when(pitanje=="Kako ste zadovoljni s trenutnom ponudom? Smjerova na diplomskom studiju na ekonomskom fakultetu u rijeci."~"zadovoljstvo ponudom smjerova",
pitanje=="Kako ste zadovoljni s ponudom obveznih izbornih kolegija na diplomskom studiju?"~"zadovoljstvo ponudom predmeta",
pitanje=="Koje su specifične prednosti fakulteta bile ključne za vašu odluku o upisu na diplomski studij."~"prednosti EFRI-ja",
pitanje=="Smatrate li da je vaš diplomski program dovoljno prilagođen trenutnim potrebama tržišta rada i potiče li razvoj vaših vještina za buduću karijeru?"~ "prilagođenost programa tržištu",
pitanje=="Kako percipirate komunikaciju između fakulteta i studenata u vezi s važnim informacijama, promjenama u programu ili poboljšanjima?"~"komunikacija fakulteta prema studentima",
pitanje=="Koje su najvažnije lekcije ili vještine koje ste do sada stekli na diplomskom studiju, a smatrate ih relevantnima za vašu buduću karijeru?"~"najvažnije vještine",
pitanje=="Jeste li sudjelovali u međunarodnim projektima i razmjenama ili tek planirate sudjelovati? Na primjer, Yufe, Cepus, Erasmus."~"sudjelovanje u razmjenama",
pitanje=="Koje konkretne mogućnosti za praktično iskustvo ili stažiranje vam fakultet pruža tijekom diplomskog studija?"~"mogućnosti prakse",
pitanje=="Kako biste opisali svoj odnos s profesorima i kolegama na diplomskom studiju?"~"odnos s profesorima",
pitanje=="Biste li preporučili drugima diplomski studij na EFRIju?"~"biste li preporučili EFRI",
pitanje=="Smatrate da fakultet pruža dovoljno resursa poput knjižnica ili online materijala kako bi podržao Vaše akademske potrebe?"~"dodatni resursi",
pitanje=="Koje biste promjene ili dodatke predložili kako biste unaprijedili vrijednost diplomskog studija na ekonomskom fakultetu?"~"preporuke za unaprjeđenje",
TRUE~pitanje)) %>%
mutate(pitanje=pitanje2) %>%
select(-pitanje2)Ovaj dio je jako važan. Dobro provjerite imate li bazu posloženu na ovaj način!
Primjer na kojem ja radim se sastoji od upravo ove 4 varijable:
## [1] "ispitanik" "spol" "pitanje" "tekst"Definicija stop-riječi
Ovdje definiramo riječi koje ne želimo u analizi (odnosno koje ne govore o sentimentu ili se ne mogu kategorizirati kao ovakve ili onakve). Ovdje ćete DODATI sve one riječi koje (kasnije u analizi) vam se kasnije u analizi pokažu kao višak. Nemojte zaboraviti nakon dodavanja nove rijeći (najlakše vam je na kraj dodati zarez, otvoriti zagradu i unijeti riječ) provesti naredbu, da te nove riječi budu spremljene u objekt CRO_STOP_WORDS i onda provesti i nanovo analizu s novim objektom CRO_STOP_WORDS
VAŽNA NAPOMENA (intervjui na engleski)
!!! Studenti koji su ispitivali studente na engleskom NE MORAJU OVAJ DIO PROVODITI jer oni već imaju bazu engleskih stop riječi koja se nalazi u objektu stop_words. VODITE RAČUNA da ćete morati izmijeniti dio (kasnije u analizama) u naredbi unnest_tokens te ćete umjesto cro_word unositi word!!! (ovo se odnosi samo na studente koji su ispitivali na engleskom!)
CRO_STOP_WORDS=tibble(cro_word=c("smo","još","ga","zbog","bila","mi","kad","i","u","uz","bez","sa",
"ne","d.o.o.","d.d.","kao","of","the",
"a","ali","nego","već","no","on","ona","će","iz","na","s","in","o",
"and","od","do","2015","2005","je","se","su","sam","si","je","ste",
"će","te","za","da","kako","koji","sve","da","rada","radu","bi",
"što","koje","rad","kroz","koja","ili","is","are","that","to"))Krenite s analizama
Prvo provjerite koje se riječi najčešće javljaju kako biste (eventualno) mogli nadopuniti CRO_STOP_WORDS objekt odmah na početku.
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
count(cro_word) %>%
arrange(-n) %>%
head()## Joining with `by = join_by(cro_word)`## # A tibble: 6 × 2
## cro_word n
## <chr> <int>
## 1 mislim 20
## 2 jako 9
## 3 možda 8
## 4 tih 8
## 5 zato 8
## 6 jer 7Meni se čini da riječi “zato” i “jer” su nebitne za kontekst, pa ću ih onda dodati CRO_STOP_WORDS objektu:
CRO_STOP_WORDS=tibble(cro_word=c("smo","još","ga","zbog","bila","mi","kad","i","u","uz","bez","sa",
"ne","d.o.o.","d.d.","kao","of","the",
"a","ali","nego","već","no","on","ona","će","iz","na","s","in","o",
"and","od","do","2015","2005","je","se","su","sam","si","je","ste",
"će","te","za","da","kako","koji","sve","da","rada","radu","bi",
"što","koje","rad","kroz","koja","ili","is","are","that","to","zato","jer"))I ponoviti analizu, ali ovaj put ću, umjesto naredbe “head” staviti naredbu View() kako bi se otovrilo u novom prozoru cijela baza pa po njoj mogu scroll-ati ili ih poredati abecedeno, ili po broju ponavljanja itd.:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
count(cro_word) %>%
arrange(-n) %>%
View()## Joining with `by = join_by(cro_word)`Zasad, ovo nam ne govori puno, još uvijek pripremamo bazu za analizu. Sljedeći korak bi bio provjeriti učestalost riječi po određenom pitanju:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
count(cro_word,pitanje) %>%
filter(n>2) %>%
ggplot(aes(x=cro_word,y=n,fill=cro_word))+
geom_col(show.legend=FALSE)+
facet_wrap(~as.factor(pitanje),scales = "free_y")+
coord_flip()## Joining with `by = join_by(cro_word)` Iz ovog grafa (za vježbu, radi se o jendom ispitaniku samo jedne grupe, vama bi trebali biti jasniji ti grafovi) nije jasno što bismo mogli zaključiti…
Analiza sentimenta:
Možda će jasnije biti ako vidimo “boju” riječi koje ispitanici koriste. Prije svega, unesite onu bazu u kojoj su riječi rangirane prema tome jesu li pozitivne ili negativne. Ta baza se nalazi na Merlinu a zove se Croatian-NRC-EmoLex.txt Unesite je na posit.cloud tako da je upload-ate a zatim Import dataset (text). Ja ću je konkretno unijeti ovom naredbom, ali da biste izbjegli potencijalne errore, napravite tako da je Import-ate direktno. Bez obzira, javit će se neki Warning (dakle ne Error), ali ga samo ignorirajte.
cro_lex <- read_delim("Croatian-NRC-EmoLex.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE)## Rows: 14154 Columns: 12
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (2): word, cro_word
## dbl (10): anger, anticipation, disgust, fear, joy, negative, positive, sadne...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Dalje moramo riječima koje su naši ispitanici koristili pridodati ocjene (pozitivnost/negativnost/neke emocije). Prije smo koristili anti_join da IZBACIMO neke riječi, sad ćemo koristiti tzv. right_join jer dodajemo te nove stvari DESNO od naše baze:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
#drop_na(portal) %>%
count(cro_word,pitanje) %>%
right_join(.,cro_lex) %>%
select(-word) %>%
distinct() %>%
#filter(n>1) %>%
arrange(-n) %>%
select(cro_word,pitanje,n,positive,negative,joy,anger,trust) %>%
distinct() %>%
group_by(pitanje) %>%
summarise(poz=sum(positive),
neg=sum(negative),
ljutnja=sum(anger),
sreca=sum(joy),
povjerenje=sum(trust))%>%
head(10) #umjesto 10 upišite neki drugi broj da dobijete manje/više## Joining with `by = join_by(cro_word)`
## Joining with `by = join_by(cro_word)`## Warning in right_join(., cro_lex): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 24 of `x` matches multiple rows in `y`.
## ℹ Row 5517 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.## # A tibble: 10 × 6
## pitanje poz neg ljutnja sreca povjerenje
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 biste li preporučili EFRI 5 2 0 2 1
## 2 dodatni resursi 4 1 0 0 1
## 3 komunikacija fakulteta prema studentima 2 1 0 1 2
## 4 mogućnosti prakse 3 1 0 0 1
## 5 najvažnije vještine 2 1 0 0 2
## 6 odnos s profesorima 2 1 0 1 4
## 7 prednosti EFRI-ja 5 1 0 1 3
## 8 preporuke za unaprjeđenje 2 0 0 0 0
## 9 prilagođenost programa tržištu 5 0 0 1 3
## 10 sudjelovanje u razmjenama 0 0 0 0 1Čak i iz ovog malo primjera (od jednog isptanika), vidimo da npr. na pitanje o odnosu s profesorima najviše riječi koje označavaju povjerenje nalazimo. Identična tablica odozgo grafički se može prikazati ovako:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
#drop_na(portal) %>%
count(cro_word,pitanje) %>%
right_join(.,cro_lex) %>%
select(-word) %>%
distinct() %>%
#filter(n>1) %>%
arrange(-n) %>%
select(cro_word,pitanje,n,positive,negative,joy,anger,trust) %>%
distinct() %>%
group_by(pitanje) %>%
summarise(poz=sum(positive),
neg=sum(negative),
ljutnja=sum(anger),
sreca=sum(joy),
povjerenje=sum(trust))%>%
head(10) %>%
pivot_longer(cols=c(poz,neg,sreca,ljutnja,povjerenje), names_to="emocija", values_to = "broj_rijeci") %>%
ggplot(aes(x=emocija,y=broj_rijeci,fill=emocija))+
geom_col(show.legend=FALSE)+
facet_wrap(~str_wrap(pitanje,width=25))+ #ovo 25 mijenjajte ako vam imena pitanja ne stanu iznad grafa nego izlaze van (onda SMANJITE BROJ)
coord_flip()## Joining with `by = join_by(cro_word)`
## Joining with `by = join_by(cro_word)`## Warning in right_join(., cro_lex): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 24 of `x` matches multiple rows in `y`.
## ℹ Row 5517 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.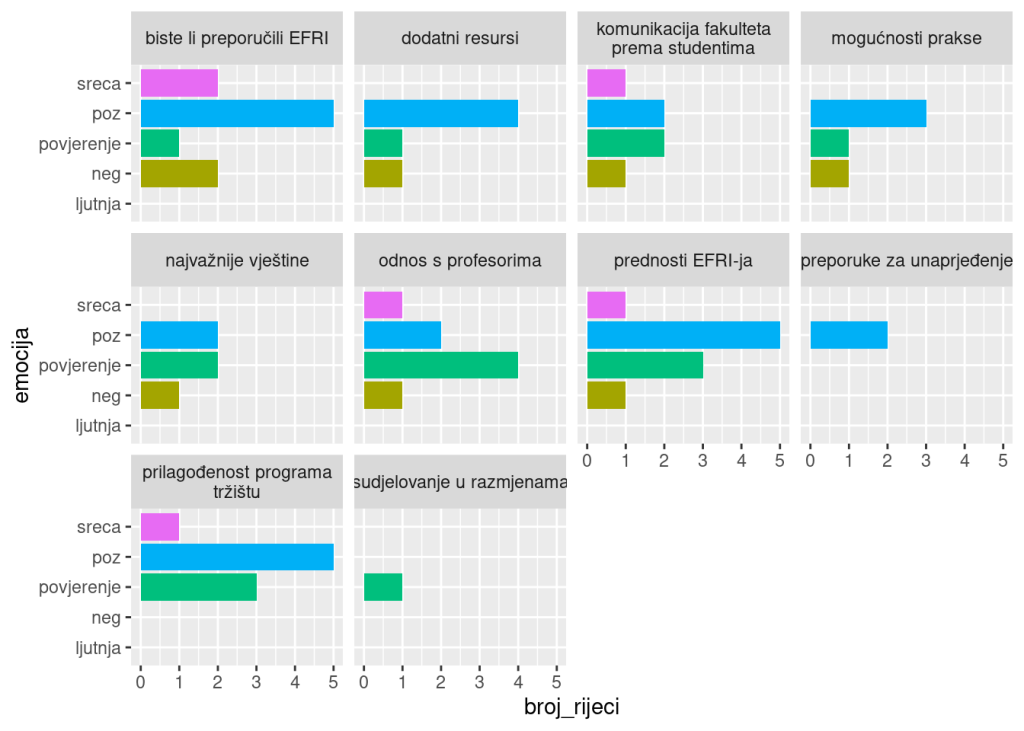
Slične riječi:
ako se pojave riječi poput “nekad” i “nekada”, bilo bi dobro da ih se tretira kao jednu riječ. To možete napraviti ovako:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
mutate(keyword=case_when(str_starts(cro_word,"dijela")~"dijelu",
#str_starts(cro_word,"RIJEČ_2")~"RIJEČ2",
#str_starts(cro_word,"RIJEČ_3")~"RIJEČ3",
# maknete hashtag i mijenjajte što treba
TRUE~cro_word))## Joining with `by = join_by(cro_word)`## # A tibble: 731 × 5
## ispitanik spol pitanje cro_word keyword
## <chr> <chr> <chr> <chr> <chr>
## 1 a m zadovoljstvo ponudom smjerova mislim mislim
## 2 a m zadovoljstvo ponudom smjerova ponuda ponuda
## 3 a m zadovoljstvo ponudom smjerova smjerova smjerova
## 4 a m zadovoljstvo ponudom smjerova diplomskom diplomskom
## 5 a m zadovoljstvo ponudom smjerova studiju studiju
## 6 a m zadovoljstvo ponudom smjerova korektna korektna
## 7 a m zadovoljstvo ponudom smjerova drugim drugim
## 8 a m zadovoljstvo ponudom smjerova faksevima faksevima
## 9 a m zadovoljstvo ponudom smjerova imaju imaju
## 10 a m zadovoljstvo ponudom smjerova možda možda
## # ℹ 721 more rowsOvaj dio (cijeli mutate) ubacite u kod analize PRIJE count()!
Kodiranje i teme
Za kraj, ako želite, možete kodirati i brojati pojavnost tema u tekstu. Npr:
brutto_baza %>%
unnest_tokens(cro_word,tekst,to_lower = T) %>%
anti_join(CRO_STOP_WORDS) %>%
mutate(tema=case_when(str_detect(cro_word,"mislim|smatram|zanimljivost")~"Kognicija", #"Kognicija je naziv teme
str_detect(cro_word,"sviđa|zabavno|ugodno")~"Emocija",
str_detect(cro_word,"ići|biti|jesam|odraditi|naučiti|prijaviti|odabrati")~"Ponašanje",
TRUE~NA)) %>%
count(tema,pitanje) %>%
drop_na() %>%
arrange(-n) %>%
View()## Joining with `by = join_by(cro_word)`Ovaj dio prilagođavajte kako želite, npr. možda ćete osmisliti i definirati svoje teme. U tom slučaju mijenjajte gornji kod tako da ime teme stavite nakon znaka ~ a riječi koje definiraju tu temu stavite između || kao u primjeru gore. Obavezno maknite riječi koje sam ja koristio.
SRETNO!